每日經濟新聞 2024-12-29 21:30:48
12月26日,DeepSeek-V3上線并同步開源。國外獨立評測機構指出,DeepSeek-V3超越了迄今為止所有開源模型。在強大的性能之外,DeepSeek-V3兩個月的訓練成本僅為558萬美元,多位技術大佬親自下場點贊。與此同時,有一個bug引發熱議:DeepSeek-V3竟聲稱自己是ChatGPT。
每經記者 鄭雨航 每經編輯 高涵 蘭素英
“DeepSeek-V3超越了迄今為止所有開源模型。”這是國外獨立評測機構Artificial Analysis測試了DeepSeek-V3后得出的結論。
12月26日,深度求索官方微信公眾號推文稱,旗下全新系列模型DeepSeek-V3首個版本上線并同步開源。
公眾號推文是這樣描述的:DeepSeek-V3為自研MoE模型,671B參數,激活37B,在14.8T token上進行了預訓練。DeepSeek-V3多項評測成績超越了Qwen2.5-72B和Llama-3.1-405B等其他開源模型,并在性能上和世界頂尖的閉源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
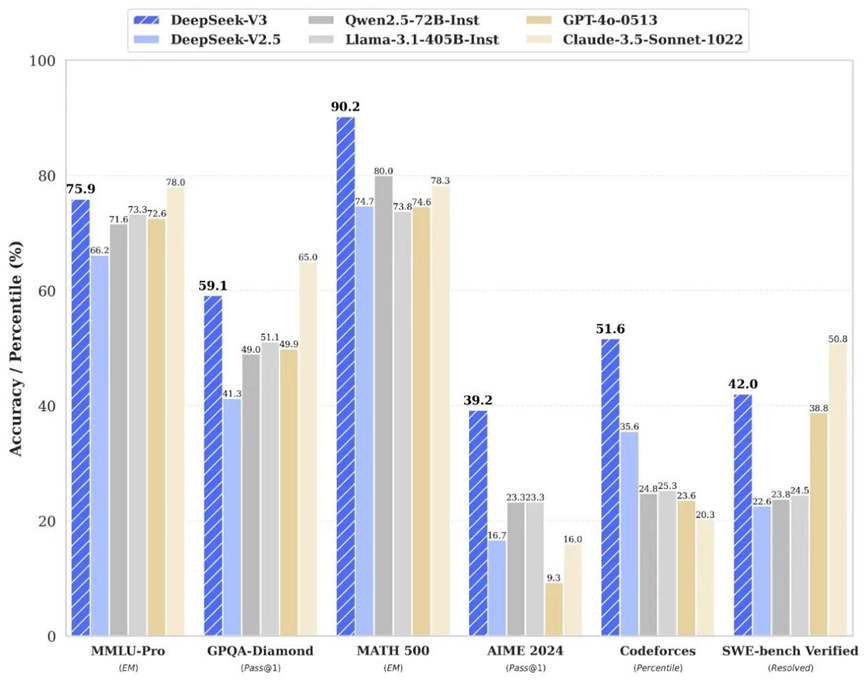
不過,廣發證券發布的測試結果顯示,DeepSeek-V3總體能力與其他大模型相當,但在邏輯推理和代碼生成領域具有自身特點。
更重要的是,深度求索使用英偉達H800 GPU在短短兩個月內就訓練出了DeepSeek-V3,僅花費了約558萬美元。其訓練費用相比GPT-4等大模型要少得多,據外媒估計,Meta的大模型Llama-3.1的訓練投資超過了5億美元。
消息一出,引發了海外AI圈熱議。OpenAI創始成員Karpathy甚至對此稱贊道:“DeepSeek-V3讓在有限算力預算上進行模型預訓練這件事變得容易。DeepSeek-V3看起來比Llama-3-405B更強,訓練消耗的算力卻僅為后者的1/11。”
然而,在使用過程中,《每日經濟新聞》記者發現,DeepSeek-V3竟然聲稱自己是ChatGPT。一時間,“DeepSeek-V3是否在使用ChatGPT輸出內容進行訓練”的質疑聲四起。
對此,《每日經濟新聞》記者采訪了機器學習奠基人之一、美國人工智能促進會前主席Thomas G. Dietterich,他表示對全新的DeepSeek模型的細節還了解不夠,無法給出確切的答案。“但從普遍情況來說,幾乎所有的大模型都主要基于公開數據進行訓練,因此沒有特別需要合成的數據。這些模型都是通過仔細選擇和清理訓練數據(例如,專注于高質量來源的數據)來取得改進。”
每經記者向深度求索公司發出采訪請求,截至發稿,尚未收到回復。
針對DeepSeek-V3,獨立評測網站Artificial Anlaysis就關鍵指標——包括質量、價格、性能(每秒生成的Token數以及首個Token生成時間)、上下文窗口等多方面——與其他人工智能模型進行對比,最終得出以下結論。
質量:DeepSeek-V3質量高于平均水平,各項評估得出的質量指數為80。

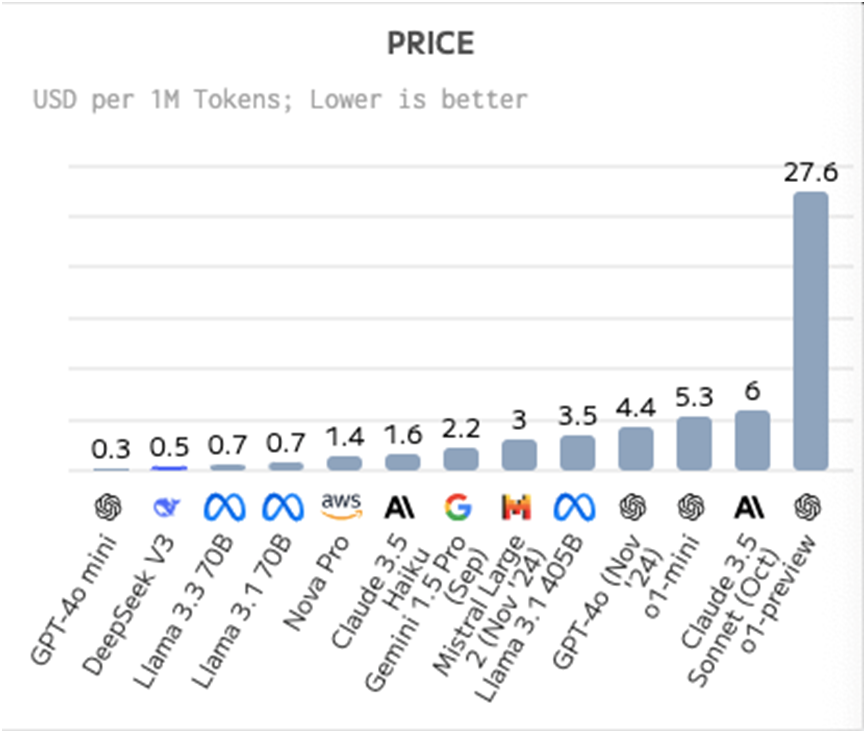
價格:DeepSeek-V3比平均價格更便宜,每100萬個Token的價格為0.48美元。其中,輸入Token價格為每100萬個Token 0.27美元,輸出Token價格為每100萬個Token1.10 美元。
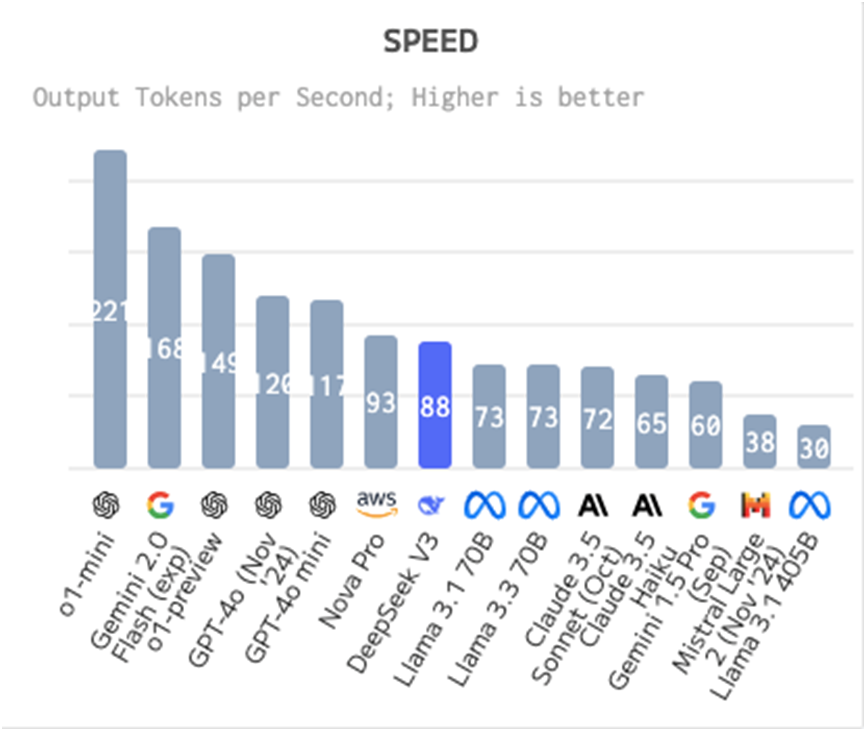
速度:DeepSeek-V3比平均速度慢,其輸出速度為每秒87.5個Token。
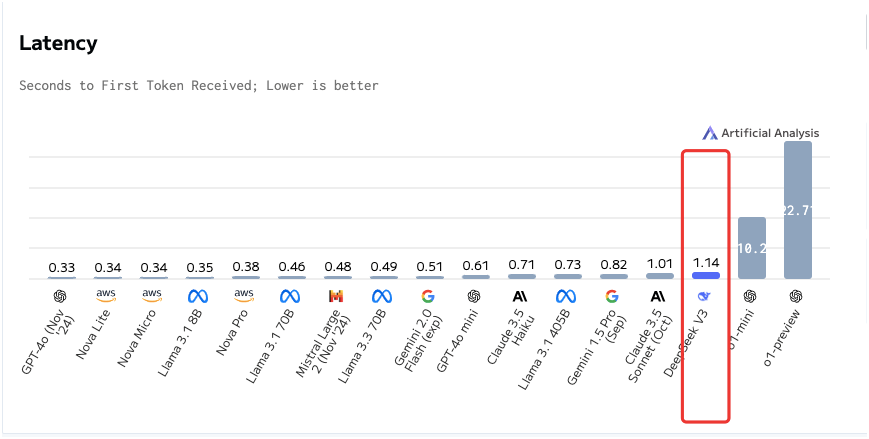
延遲:DeepSeek-V3與平均水平相比延遲更高,接收首個Token(即首字響應時間)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口為13萬個Token。
最終Artificial Anlaysis得出結論:
“DeepSeek-V3模型超越了迄今為止發布的所有開放權重模型,并且擊敗了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析質量指數得分為80,領先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然領先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。領先于阿里巴巴的Qwen2.5 72B,DeepSeek現在是中國的AI領先者。”
12月29日廣發證券計算機行業分析師發布研報稱:“為了深入探索DeepSeek-V3的能力,我們采用了覆蓋邏輯、數學、代碼、文本等領域的多個問題對模型進行測試,將其生成結果與豆包、Kimi以及通義千問大模型生成的結果進行比較。”
測試結果顯示,DeepSeek-V3總體能力與其他大模型相當,但在邏輯推理和代碼生成領域具有自身特點。例如,在密文解碼任務中,DeepSeek-V3是唯一給出正確答案的大模型;而在代碼生成的任務中,DeepSeek-V3給出的代碼注釋、算法原理解釋以及開發流程的指引是最為全面的。在文本生成和數學計算能力方面,DeepSeek-V3并未展現出明顯優于其他大模型之處。
除了能力,DeepSeek-V3最讓業內驚訝的是它的低價格和低成本。
《每日經濟新聞》記者注意到,亞馬遜Claude 3.5 Sonnet模型的API價格為每百萬輸入tokens 3美元、輸出15美元。也就是說,即便是不按照優惠價格,DeepSeek-V3的使用費用也幾乎是Claude 3.5 Sonnet的五十三分之一。
相對低廉的價格,得益于DeepSeek-V3的訓練成本控制,深度求索在短短兩個月內使用英偉達H800 GPU數據中心就訓練出了DeepSeek-V3模型,花費了約558萬美元。其訓練費用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,據外媒估計,Meta的大模型Llama-3.1的訓練投資超過了5億美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通過數據與算法層面的優化,大幅提升算力利用效率,實現了協同效應。在大規模MoE模型的訓練中,DeepSeek-V3采用了高效的負載均衡策略、FP8混合精度訓練框架以及通信優化等一系列優化措施,顯著降低了訓練成本,以及通過優化MoE專家調度、引入冗余專家策略、以及通過長上下文蒸餾提升推理性能。這證明,模型效果不僅依賴于算力投入,即使在硬件資源有限的情況下,依托數據與算法層面的優化創新,仍然可以高效利用算力,實現較好的模型效果。
廣發證券分析稱,DeepSeek-V3算力成本降低的原因有兩點。
第一,DeepSeek-V3采用的DeepSeekMoE是通過參考了各類訓練方法后優化得到的,避開了行業內AI大模型訓練過程中的各類問題。
第二,DeepSeek-V3采用的MLA架構可以降低推理過程中的kv緩存開銷,其訓練方法在特定方向的選擇也使得其算力成本有所降低。
科技媒體Maginative的創始人兼主編Chris McKay對此評論稱,對于人工智能行業來說,DeepSeek-V3代表了一種潛在的范式轉變,即大型語言模型的開發方式。這一成就表明,通過巧妙的工程和高效的訓練方法,可能無需以前認為必需的龐大計算資源,就能實現人工智能的前沿能力。
他還表示,DeepSeek-V3的成功可能會促使人們重新評估人工智能模型開發的既定方法。隨著開源模型與閉源模型之間的差距不斷縮小,公司可能需要在一個競爭日益激烈的市場中重新評估他們的策略和價值主張。
不過,廣發證券分析師認為,算力依然是推動大模型發展的核心驅動力。DeepSeek-V3的技術路線得到充分驗證后,有望驅動相關AI應用的快速發展,應用推理驅動算力需求增長的因素也有望得到增強。尤其在實際應用中,推理過程涉及到對大量實時數據的快速處理和決策,仍然需要強大的算力支持。
在DeepSeek-V3刷屏之際,有一個bug也引發熱議。
在試用DeepSeek-V3過程中,《每日經濟新聞》記者在對話框中詢問“你是什么模型”時,它給出了一個令人詫異的回答:“我是一個名為ChatGPT的AI語言模型,由OpenAl開發。”此外,它還補充說明,該模型是“基于GPT-4架構”。

國內外很多用戶也都反映了這一現象。而且,12月27日,Sam Altman發了一個帖文,外媒指出,Altman這篇推文意在暗諷其競爭對手對OpenAI數據的挖掘。

于是,有人就開始質疑:DeepSeek-V3是否是在ChatGPT的輸出基礎上訓練的?為此,《每日經濟新聞》向深度求索發出采訪請求。截至發稿,尚未收到回復。
針對這種情況產生的原因,每經記者采訪了機器學習奠基人之一、美國人工智能促進會前主席Thomas G. Dietterich,他表示,他對全新的DeepSeek模型的細節還了解不夠,無法給出確切的答案。“但從普遍情況來說,幾乎所有的大模型都主要基于公開數據進行訓練,因此沒有特別需要合成的數據。這些模型都是通過仔細選擇和清理訓練數據(例如,專注于高質量來源的數據)來取得了改進。”
TechCrunch則猜測稱,深度求索可能用了包含GPT-4通過ChatGPT生成的文本的公共數據集。“如果DeepSeek-V3是用這些數據進行訓練的,那么該模型可能已經記住了GPT-4的一些輸出,現在正在逐字反芻它們。”
“顯然,該模型(DeepSeek-V3)可能在某些時候看到了ChatGPT的原始反應,但目前尚不清楚從哪里看到的,”倫敦國王學院專門研究人工智能的研究員Mike Cook也指出,“這也可能是個‘意外’。”他進一步解釋稱,根據競爭對手AI系統輸出訓練模型的做法可能對模型質量產生“非常糟糕”的影響,因為它可能導致幻覺和誤導性答案。
不過,DeepSeek-V3也并非是第一個錯誤識別自己的模型,谷歌的Gemini等有時也會聲稱是競爭模型。例如,Gemini在普通話提示下稱自己是百度的文心一言聊天機器人。
造成這種情況的原因可能在于,AI公司在互聯網上獲取大量訓練數據,但是,現如今的互聯網本就充斥著各種各樣用AI生產出來的數據。據外媒估計,到2026年,90%的互聯網數據將由AI生成。這種 “污染” 使得從訓練數據集中徹底過濾AI輸出變得相當困難。
“互聯網數據現在充斥著AI輸出,”非營利組織AI Now Institute的首席AI科學家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型進行提煉數據,也不足為奇。
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














