每日經(jīng)濟新聞 2025-02-18 21:05:42
當?shù)貢r間2月17日晚,馬斯克旗下AI公司xAI發(fā)布了Grok 3及其精簡版Grok 3 mini。馬斯克在發(fā)布會上聲稱,Grok 3在包括AIME和GPQA在內(nèi)的基準測試中擊敗了所有市面上的模型。然而,有用戶指出Grok 3在游戲相關(guān)結(jié)論和編程問題上出現(xiàn)了錯誤。OpenAI聯(lián)合創(chuàng)始人Andrej Karpathy在短暫的上手體驗后認為,Grok 3 + Thinking與ChatGPT的o1-pro差不多,略好于DeepSeek-R1和谷歌的Gemini 2.0 Flash Thinking。
每經(jīng)記者 岳楚鵬 每經(jīng)編輯 蘭素英
一度“跳票”的AI模型Grok 3終于迎來正式發(fā)布。
當?shù)貢r間2月17日晚,馬斯克旗下AI公司xAI發(fā)布了Grok 3及其精簡版Grok 3 mini。發(fā)布會采用視頻直播形式,觀看人數(shù)超過100萬人。
Grok 3是xAI對OpenAI的o3-mini和DeepSeek的R1等模型的回應(yīng),它可以分析圖像和回答問題,并為X上的許多功能提供支持。前天馬斯克就在X上造勢稱,Grok 3是“地球上最聰明的人工智能”。
圖片來源:直播截圖
在發(fā)布會上,馬斯克和三位xAI的工程師一起演示了Grok 3的各種功能。馬斯克在直播演示中聲稱,Grok 3在包括AIME(測試模式在數(shù)學問題上的表現(xiàn))和GPQA(測試模型在博士級物理、生物和化學問題上的表現(xiàn))在內(nèi)的基準測試中擊敗了所有的市面上所有模型。
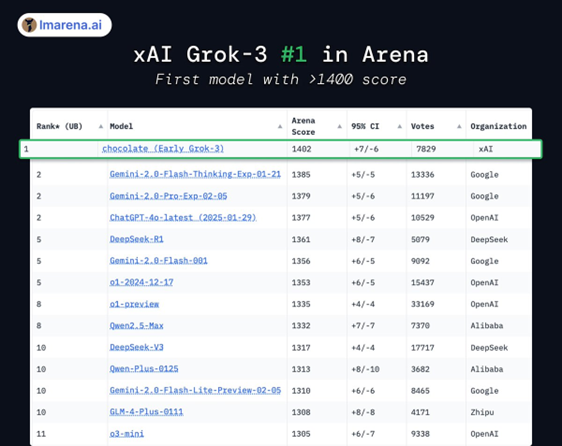
馬斯克似乎也并非在打“誑語”。從AI基準測試開放平臺lmarena.ai放出的截圖看,測試數(shù)據(jù)顯示,早期版本的Grok 3(代號chocolate)在Arena排行榜上拿下了第一,吊打其他主流AI大模型,并且,Grok 3還是第一個獲得超過1400分的模型。
然而,有用戶在觀看發(fā)布會后指出,Grok 3給出的關(guān)于《流放之路2》游戲的結(jié)論錯誤頻出,另有用戶測試發(fā)現(xiàn),Grok 3在經(jīng)典的多邊形小球編程問題上也出現(xiàn)了錯誤。
OpenAI聯(lián)合創(chuàng)始人Andrej Karpathy也在發(fā)布會后放出了自己的感想。他認為,就目前短暫上手的體驗而言,Grok 3 + Thinking感覺與ChatGPT的o1-pro差不多,略好于DeepSeek-R1和谷歌的Gemini 2.0 Flash Thinking。
早在2024年7月,馬斯克在與喬丹·彼得森的訪談節(jié)目時就表示,Grok 3預(yù)計將在2024年12月底發(fā)布。但到了年底,這個承諾并沒有兌現(xiàn),一度有人懷疑這只不過是馬斯克無數(shù)個大餅中的其中一個,Grok 3或許遙遙無期。
不過,在上周的迪拜峰會上,馬斯克卻突然宣布,xAI將在一到兩周內(nèi)推出新一代AI模型Grok 3,而這個模型的強大程度,用他的話說,“強到讓人感到害怕”。馬斯克甚至預(yù)言這可能是“最后一次有AI比Grok更優(yōu)秀”。
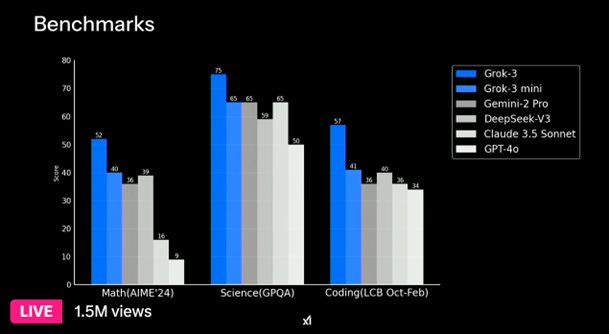
從xAI在直播中放出的基準測試結(jié)果來看,Grok 3在數(shù)學、科學和編程領(lǐng)域的表現(xiàn)大幅領(lǐng)先于市面上其他主流的AI模型。
在數(shù)學能力測試(AIME'24)中,Grok 3獲得52分,明顯超過DeepSeek-V3的39分和GPT-4o的9分;在科學知識評估(GPQA)中,Grok 3以75分的成績領(lǐng)先,而DeepSeek-V3和GPT-4o的得分分別為65分和50分;在編程能力測試(LCB Oct-Feb)中,Grok 3同樣以57分超過DeepSeek-V3的36分合GPT-4o的34分。
圖片來源:xAI
在推理模型的比較中,Grok 3 Reasoning Beta也戰(zhàn)勝了OpenAI的o3-mini、DeepSeek的R1和Gemini-2 Flash Thinking等推理模型。不過,演示團隊表示允許Grok去進行更長時間的思考和推理。

圖片來源:xAI
AI基準測試開放平臺lmarena.ai也爆出猛料,最新測試數(shù)據(jù)顯示,早期版本的Grok 3(代號chocolate)在經(jīng)過約8000次投票后,在Arena排行榜上拿下第一。
圖片來源:X
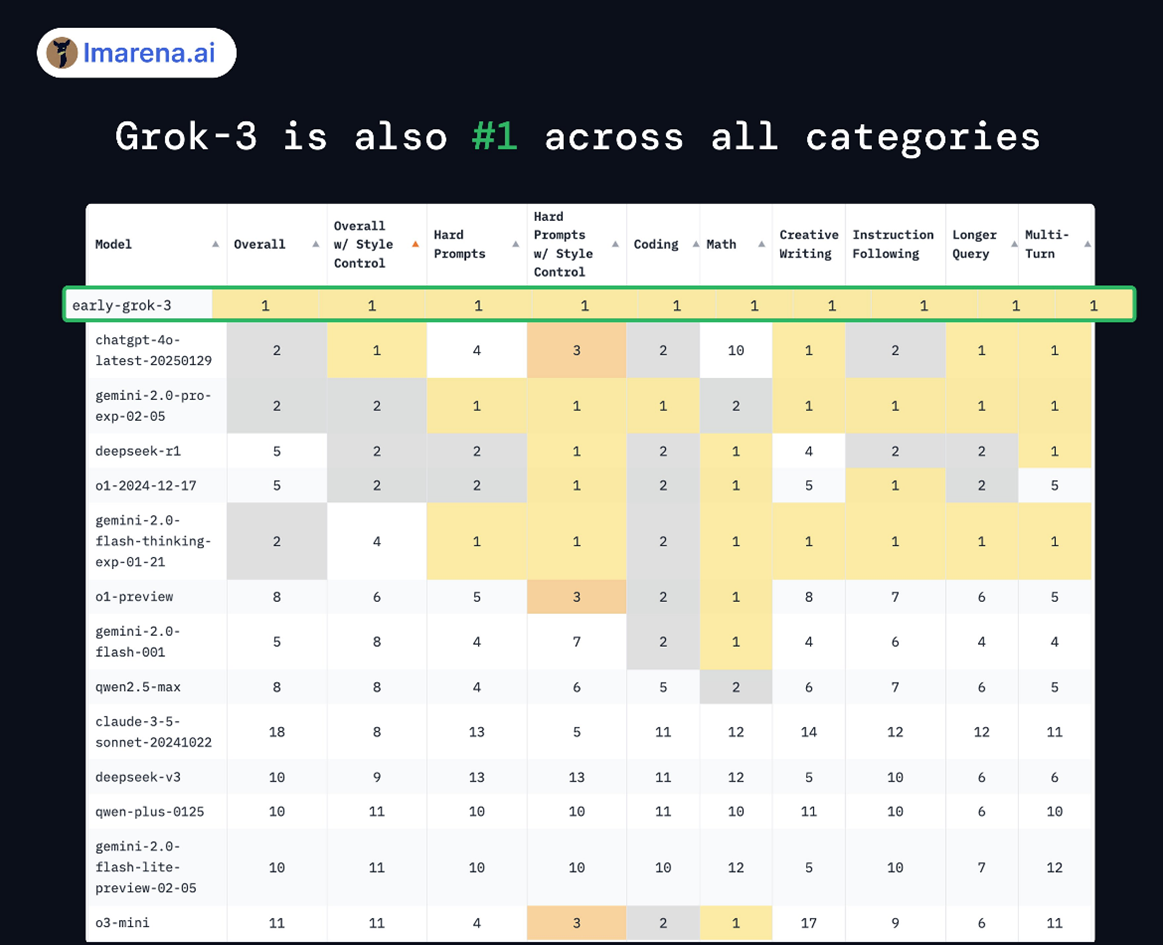
lmarena.ai稱,Grok 3是第一個突破了1400分的模型,并且在所有分類中都排名第一,而這一里程碑以后會越來約難以實現(xiàn)。
圖片來源:X
和DeepSeek從技術(shù)層面對模型進行改進不同,馬斯克的新模型還是屬于“大力出奇跡”。
此前有新聞報道,馬斯克組建了一個配有十萬塊H100 GPU的、世界上最大的超級計算機集群Colossus來幫助訓練Grok模型。在此次直播中,馬斯克透露,實際上,到訓練進行到92天時,集群的規(guī)模已經(jīng)擴大到了20萬塊GPU。

圖片來源:xAI
也難怪有人說Grok 3是終極的Scaling Law測試了,是靠吞噬算力訓練起來的怪物。
演示團隊為了使大家更直觀地了解Grok 3的強大之處,還演示了物理學和游戲的例子。
首先,要求Grok 3生成一段代碼繪制從地球發(fā)射火箭,降落在火星,然后在下一個發(fā)射窗口返回地球的三維動畫圖表。這一任務(wù)涉及大量的數(shù)學和物理計算,極具挑戰(zhàn)性。Grok 3很快生成了完整的動畫,研究人員在檢查后表示結(jié)果完全正確。
圖片來源:xAI
之后,演示團隊又要求Grok編寫一個結(jié)合俄羅斯方塊和寶石迷城的游戲,Grok也順利完成了任務(wù)。
除了基本的模型能力之外,Grok 3也具備智能體功能。
xAI為Grok 3開發(fā)了一個類似于OpenAI的DeepSearch智能體。DeepSearch可以對互聯(lián)網(wǎng)進行全面搜索,并為用戶提供詳盡的整合報告。馬斯克表示,這可以省下你幾十次谷歌搜索的時間,而公司將得到幾十億美元的回報。
在演示團隊的展示中,Grok 3似乎無所不能,拳打OpenAI,腳踢Deepseek,已然站上世界AI模型的巔峰,但有些觀看了演示和迫不及待體驗了Grok 3的用戶卻發(fā)現(xiàn)了一些奇怪的問題。
在發(fā)布會中,為了演示DeepSearch功能,演示團隊就馬斯克最近在玩的游戲《流放之路2》詢問了一個相關(guān)問題。有游戲博主看后表示,Grok 3給出的游戲結(jié)論錯誤頻出,感覺不如馬斯克宣稱的那么聰明。
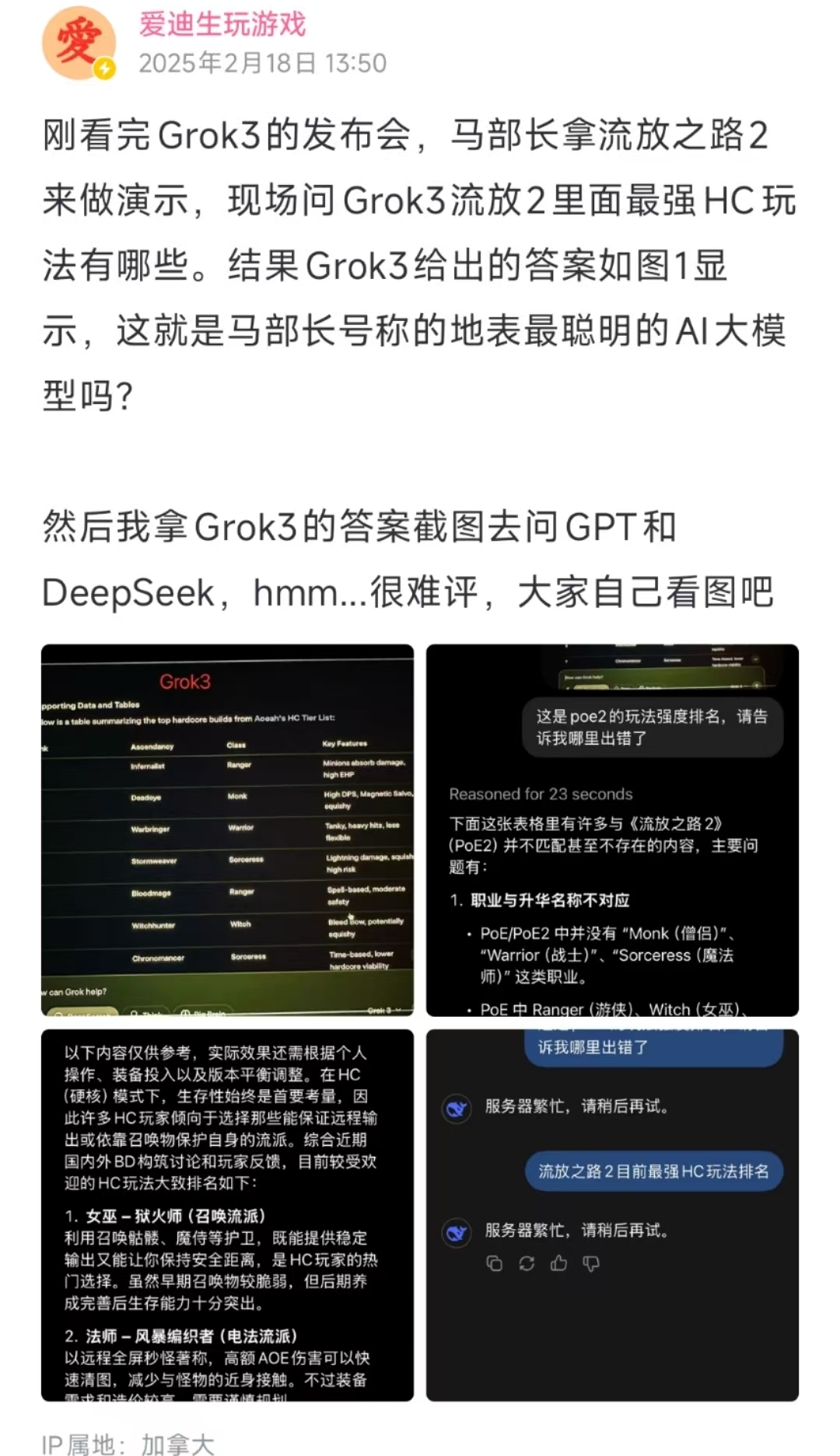
圖片來源:嗶哩嗶哩
有專門直播該游戲的游戲博主也對《每日經(jīng)濟新聞》記者表示,Grok 3給出的答案沒一個是對的,不如GPT。
另外,有用戶體驗了Grok 3的編程功能,隨后也表示,Grok 3的編程能力并不是很強大。在經(jīng)典的多邊形小球編程問題上,Grok 3出現(xiàn)了錯誤。

圖片來源:X
OpenAI聯(lián)合創(chuàng)始人Andrej Karpathy作為為數(shù)不多的提前拿到測試資格的人,也在發(fā)布會后放出了自己的感想。他認為,就目前短暫上手的體驗而言,Grok 3 + Thinking感覺與ChatGPT的o1-pro差不多,略好于DeepSeek-R1和谷歌的Gemini 2.0 Flash Thinking。
Karpathy表示,Grok 3顯然有一個最先進的思維模型,并且在卡坦島定居者問題上做得很好。很少有模型能夠可靠做到這一點。頂級的OpenAI推理模型(如o1-pro,月訂閱費為200美元)也能做到這一點,但DeepSeek-R1、Gemini 2.0 Flash Thinking和Claude的所有模型都沒辦法做到。
但Grok 3并沒有解決“表情符號之謎”問題,即使以Rust代碼的形式給出了有關(guān)如何解碼它的強烈提示。而在這點上,Karpathy稱其見過的最大進展來自DeepSeek-R1,它曾經(jīng)部分解碼了消息。
此外,Karpathy認為,DeepSearch大約等于Perplexity DeepResearch的產(chǎn)品,但還沒有達到OpenAI最近發(fā)布的“深度研究”的水平。
不過,他同時也指出,考慮到xAI團隊在大約在1年前從頭開始,這是相當令人難以置信的,達到最先進領(lǐng)域的時間跨度是前所未有的。目前得出完整結(jié)論還為時過早,需要在在接下來的幾天/幾周內(nèi)等待更多的評估。
如需轉(zhuǎn)載請與《每日經(jīng)濟新聞》報社聯(lián)系。
未經(jīng)《每日經(jīng)濟新聞》報社授權(quán),嚴禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟新聞APP

Copyright ? 2025 每日經(jīng)濟新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112













