每日經(jīng)濟(jì)新聞 2025-03-01 18:23:59
3月1日,DeepSeek在知乎發(fā)文,揭曉V3/R1推理系統(tǒng)關(guān)鍵秘密。該系統(tǒng)通過大規(guī)模跨節(jié)點(diǎn)專家并行等技術(shù)策略,實(shí)現(xiàn)更大吞吐、更低延遲。同時(shí),文章還披露其理論成本和利潤率等信息。此外,DeepSeek近期動(dòng)作頻頻,2月21日宣布連續(xù)五天開源五大軟件庫,25日將DeepEP向公眾開放,短時(shí)間內(nèi)獲超千個(gè)Star收藏。
每經(jīng)編輯 張錦河
3月1日,DeepSeek在知乎上發(fā)表題為《DeepSeek-V3/R1 推理系統(tǒng)概覽》的文章,全面揭曉V3/R1 推理系統(tǒng)背后的關(guān)鍵秘密。

據(jù)文章介紹,DeepSeek-V3/R1推理系統(tǒng)的優(yōu)化目標(biāo)是更大的吞吐、更低的延遲。為了實(shí)現(xiàn)這兩個(gè)目標(biāo),DeepSeek使用了大規(guī)模跨節(jié)點(diǎn)專家并行(Expert Parallelism / EP)的方法,并通過一系列技術(shù)策略,最大程度地優(yōu)化了大模型推理系統(tǒng),實(shí)現(xiàn)了驚人的性能和效率。
具體而言,在更大的吞吐的方面,大規(guī)模跨節(jié)點(diǎn)專家并行能夠使得batch size(批尺寸)大大增加,從而提高GPU矩陣乘法的效率,提高吞吐。
batch size在深度學(xué)習(xí)中是一個(gè)非常重要的超參數(shù),指模型在訓(xùn)練過程中每次使用的數(shù)據(jù)量大小。它決定了每次模型更新時(shí)使用的訓(xùn)練樣本數(shù)量,調(diào)整batch size可以影響模型的訓(xùn)練速度、內(nèi)存消耗以及模型權(quán)重的更新方式。
在更低的延遲方面,大規(guī)模跨節(jié)點(diǎn)專家并行使得專家分散在不同的GPU上,每個(gè)GPU只需要計(jì)算很少的專家(因此更少的訪存需求),從而降低延遲。
但是,由于大規(guī)模跨節(jié)點(diǎn)專家并行會(huì)大幅增加系統(tǒng)的復(fù)雜性,帶來了跨節(jié)點(diǎn)通信、多節(jié)點(diǎn)數(shù)據(jù)并行、負(fù)載均衡等挑戰(zhàn),因此DeepSeek在文章中也重點(diǎn)論述了使用大規(guī)模跨節(jié)點(diǎn)專家并行增大batch size的同時(shí),如何隱藏傳輸?shù)暮臅r(shí),如何進(jìn)行負(fù)載均衡。
具體來看,DeepSeek團(tuán)隊(duì)主要通過規(guī)模化跨節(jié)點(diǎn)專家并行、雙批次重疊策略、最優(yōu)負(fù)載均衡等方式,最大化資源利用率,保證高性能和穩(wěn)定性。
值得注意的是,文章還披露了DeepSeek的理論成本和利潤率等關(guān)鍵信息。據(jù)介紹,DeepSeek V3 和R1的所有服務(wù)均使用英偉達(dá)的H800 GPU,由于白天的服務(wù)負(fù)荷高,晚上的服務(wù)負(fù)荷低,DeepSeek實(shí)現(xiàn)了一套機(jī)制,在白天負(fù)荷高的時(shí)候,用所有節(jié)點(diǎn)部署推理服務(wù)。晚上負(fù)荷低的時(shí)候,減少推理節(jié)點(diǎn),以用來做研究和訓(xùn)練。
通過時(shí)間上的成本控制,DeepSeek表示DeepSeek V3和R1推理服務(wù)占用節(jié)點(diǎn)總和,峰值占用為278個(gè)節(jié)點(diǎn),平均占用226.75個(gè)節(jié)點(diǎn)(每個(gè)節(jié)點(diǎn)為8個(gè)H800 GPU)。假定GPU租賃成本為2美元/小時(shí),總成本為87072美元/天;如果所有tokens全部按照DeepSeek R1的定價(jià)計(jì)算,理論上一天的總收入為562027美元/天,成本利潤率為545%。
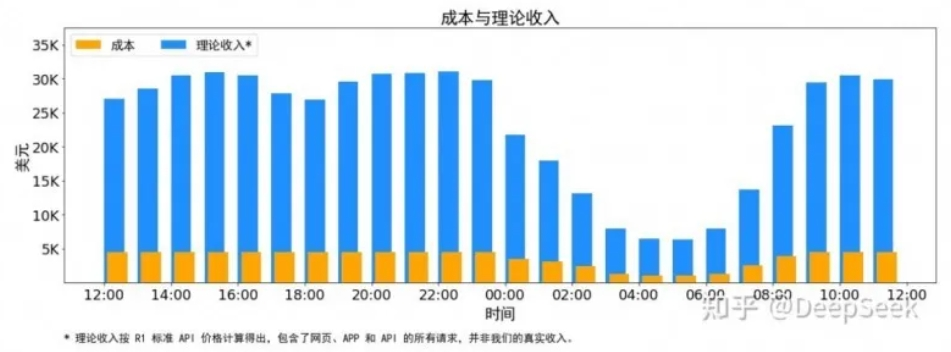
不過,DeepSeek也強(qiáng)調(diào),實(shí)際上的收入或許并沒有那么多,因?yàn)閂3的定價(jià)相較于R1要更低,另外夜間還會(huì)有折扣。記者注意到,2月26日,DeepSeek在其API開放平臺(tái)發(fā)布錯(cuò)峰優(yōu)惠活動(dòng)通知。根據(jù)通知,北京時(shí)間每日00:30-08:30為錯(cuò)峰時(shí)段,API調(diào)用價(jià)格大幅下調(diào),其中DeepSeek-V3降至原價(jià)的50%,DeepSeek-R1降至25%。DeepSeek鼓勵(lì)用戶在該時(shí)段調(diào)用,享受更經(jīng)濟(jì)更流暢的服務(wù)體驗(yàn)。
上周五(2月21日),DeepSeek宣布連續(xù)五天開源五大軟件庫。2月25日DeepSeek選擇了先在GitHub上線,然后再在官推發(fā)布上新通知。該公司25日宣布將DeepEP向公眾開放。在宣布后的約20分鐘內(nèi),DeepEP已在GitHub、微軟(MSFT.US)等平臺(tái)上獲得超過1000個(gè)Star收藏。

據(jù)悉,DeepEP是MoE模型訓(xùn)練和推理的ExpertParallelism通信基礎(chǔ),可實(shí)現(xiàn)高效優(yōu)化的全到全通信,以支持包括FP8在內(nèi)的低精度計(jì)算,適用于現(xiàn)代高性能計(jì)算。DeepEP還針對(duì)從NVLink到RDMA的非對(duì)稱帶寬轉(zhuǎn)發(fā)場(chǎng)景進(jìn)行了深度優(yōu)化,不僅提供高吞吐量,還支持流式多處理器數(shù)量控制,從而在訓(xùn)練和推理任務(wù)中實(shí)現(xiàn)高吞吐量性能。
每日經(jīng)濟(jì)新聞綜合自公開信息
免責(zé)聲明:本文內(nèi)容與數(shù)據(jù)僅供參考,不構(gòu)成投資建議,使用前請(qǐng)核實(shí)。據(jù)此操作,風(fēng)險(xiǎn)自擔(dān)。
如需轉(zhuǎn)載請(qǐng)與《每日經(jīng)濟(jì)新聞》報(bào)社聯(lián)系。
未經(jīng)《每日經(jīng)濟(jì)新聞》報(bào)社授權(quán),嚴(yán)禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請(qǐng)作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟(jì)新聞APP

Copyright ? 2025 每日經(jīng)濟(jì)新聞報(bào)社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












