每日經濟新聞 2025-03-26 19:17:04
當地時間3月25日,谷歌正式推出全新AI模型系列——Gemini 2.5。該系列的首發產品Gemini 2.5 Pro一經發布,便在各大基準測試中全面“屠榜”,在編程、數學和科學等方面表現出色。每經記者實測發現,Gemini 2.5 Pro的確實力強大,可輕松模擬火星登陸,快速制作小游戲,但在設計審美方面還有提升空間。
每經記者 岳楚鵬 每經編輯 蘭素英

圖片來源:谷歌博客
當地時間3月25日,谷歌正式揭開其下一代AI模型系列——Gemini 2.5的神秘面紗,宣稱這是其迄今為止“最智能的AI模型”。
首個發布的版本被命名為Gemini 2.5 Pro Experimental(以下簡稱“Gemini 2.5 Pro”)。谷歌表示,Gemini 2.5 Pro支持100萬個token的上下文窗口,這意味著AI模型能一次性處理相當于兩本《紅樓夢》字數的文本量。
該模型一經發布,便在各大基準測試上全面“屠榜”,在所有測試中都穩居第一名的位置,包括常見的編程、數學和科學基準測試。
谷歌Deepmind首席技術官Koray Kavukcuoglu在博客中寫道:“現在,通過Gemini 2.5,我們結合了顯著增強的基礎模型和改進后的后續訓練,實現了全新的性能水平。未來,我們將把這種思維能力直接構建到我們所有的模型中,使其能夠處理更復雜的問題,并支持更強大、更具情境感知能力的智能體。”
《每日經濟新聞》記者(以下簡稱“每經記者”)也在第一時間對Gemini 2.5 Pro進行了測試,測試包括數學、火星登陸模擬測試、網頁開發和小游戲制作。
測試結果顯示,該模型在科學類問題和編程方面實力強大,用戶只要會打字,就能進行編程。而且,生成速度極快,質量良好。與每經記者之前測試的多款大模型相比,Gemini 2.5 Pro在測試過程中幾乎沒有出現bug。不過,在網頁設計審美和玩家體驗等方面,該模型還有提升的空間。
當地時間3月25日,谷歌宣布推出全新AI模型系列——Gemini 2.5。谷歌首席科學家Jeff Dean表示,Gemini 2.5是該公司最智能的模型,具有令人印象深刻的高級推理和編碼能力。
Gemini 2.5系列屬于“思考模型”,這意味著該模型在生成最終回應之前,能夠進行內部的“思考”或推理過程。谷歌表示,這種能力旨在顯著提升模型的性能表現和答案的準確性,是谷歌在強化學習、思維鏈提示技術領域長期深耕,以及對早期 “思考” 模型(如 Gemini 2.0 Flash Thinking )持續探索的重要成果。
Gemini 2.5 Pro是這一系列模型的首發產品。谷歌表示,Gemini 2.5 Pro支持100萬個token的上下文窗口,這意味著它一次性能處理相當于兩本《紅樓夢》字數的文本量。并且,谷歌承諾,Gemini 2.5 Pro很快將支持兩倍的上下文窗口(即200萬個token)。
目前,Gemini 2.5 Pro已在Google AI Studio和Gemini應用中推出,向Gemini Advanced用戶開放,并將很快在Vertex AI上推出。
一經發布,Gemini 2.5 Pro便以出色的性能吸引了外界的廣泛關注。谷歌在博客中強調,Gemini 2.5 Pro在一系列行業基準測試中達到了“最先進水平”(state-of-the-art),包括常見的編程、數學和科學基準測試。
在“人類的最后考試”測試中,它獲得了18.8%的最高分數,這是目前為止所有未使用(外接工具)的大模型中最好的成績。?“人類最后的考試”是一個由全球近千名專家共同設計的多模態基準測試,旨在評估大型語言模型的能力極限。?該測試包含3000道涵蓋數學、人文學科和自然科學等多個領域的前沿問題。
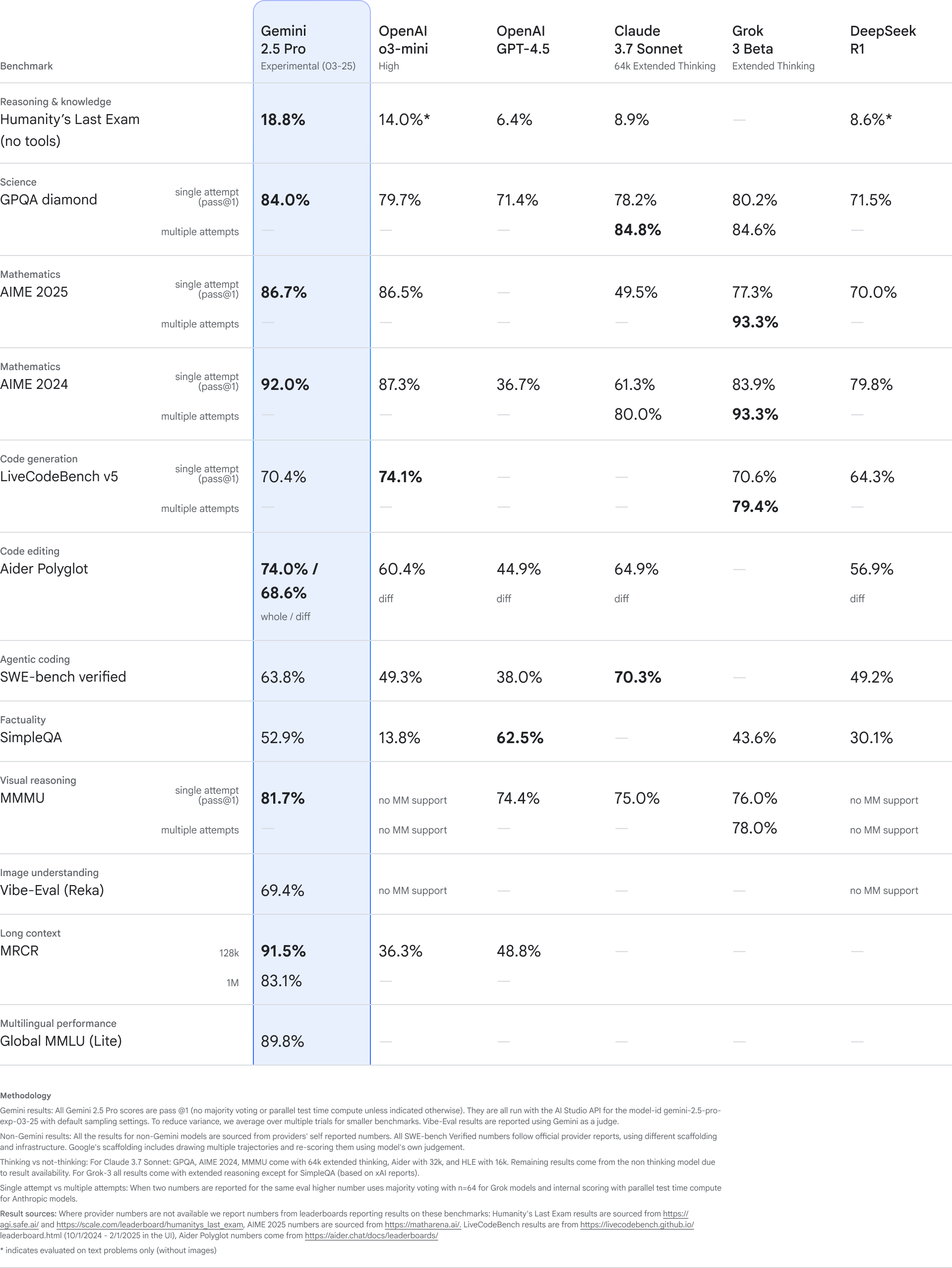
“人類的最后考試”測試 圖片來源:谷歌官網
在專注于人類理解的大模型競技場測試中,Gemini 2.5 Pro也以創紀錄的優勢拔得頭籌,創下了歷史最大的分數跨越,比Grok-3和GPT-4.5高出40多分。
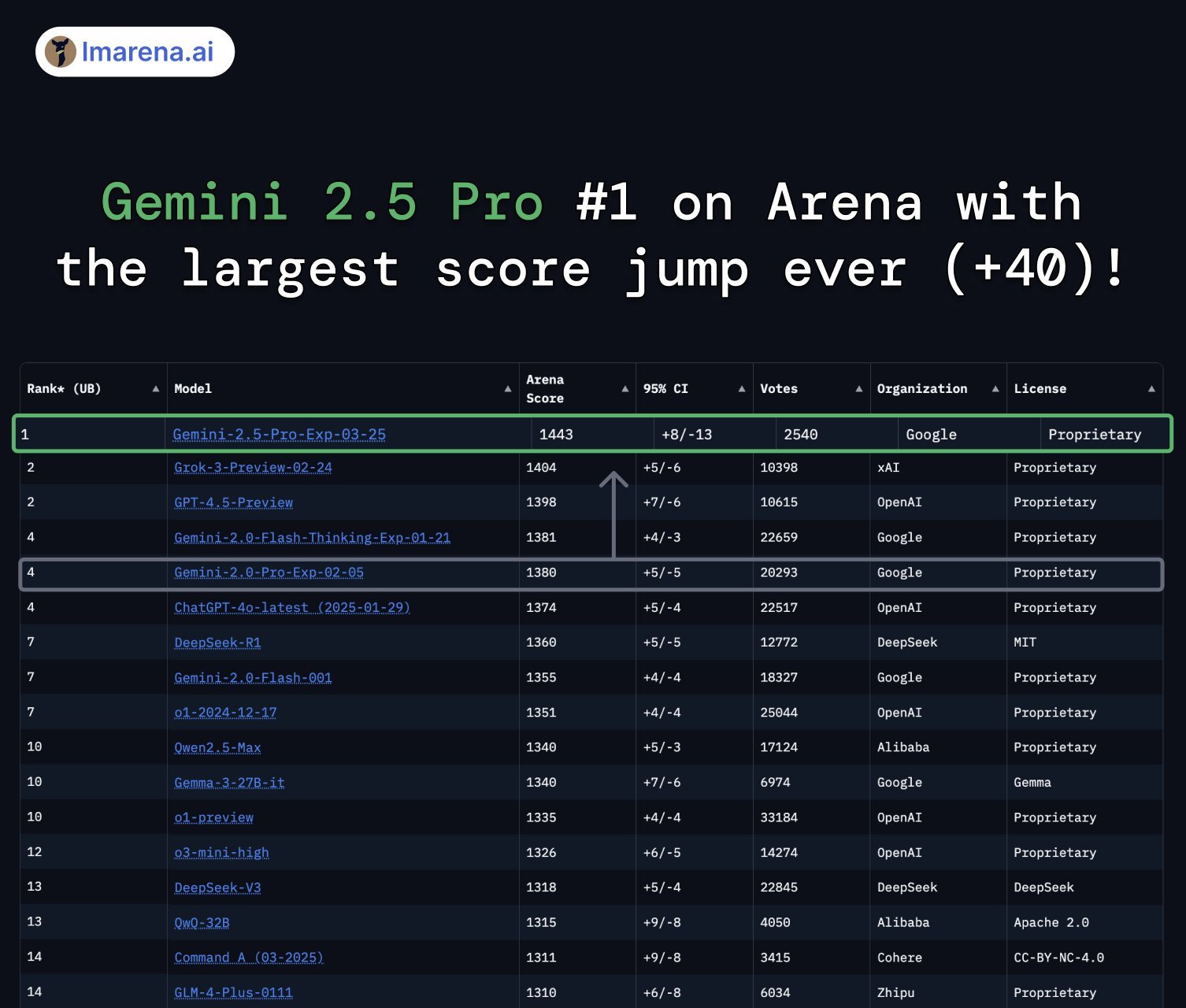
圖片來源:大模型競技場
具體來看,在代號為“nebula”的測試中,Gemini 2.5 Pro橫掃所有類別,奪得第一,獨攬數學、創意寫作、指令遵循、長查詢和多輪對話這五大領域的冠軍;
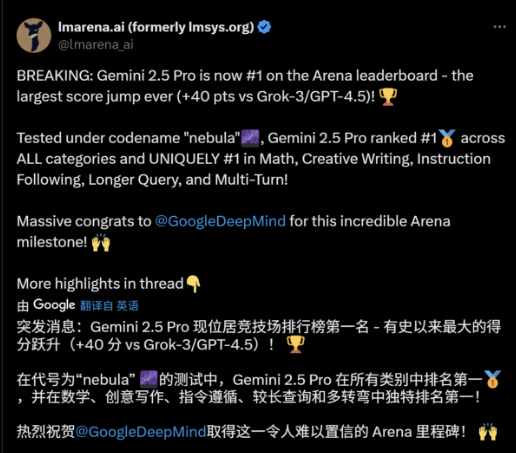
圖片來源:X平臺截圖
在人類偏好測試中,Gemini 2.5 Pro同樣是在所有類別中問鼎榜首,只在困難提示和編碼領域與Grok-3/GPT-4.5拿到并列冠軍。
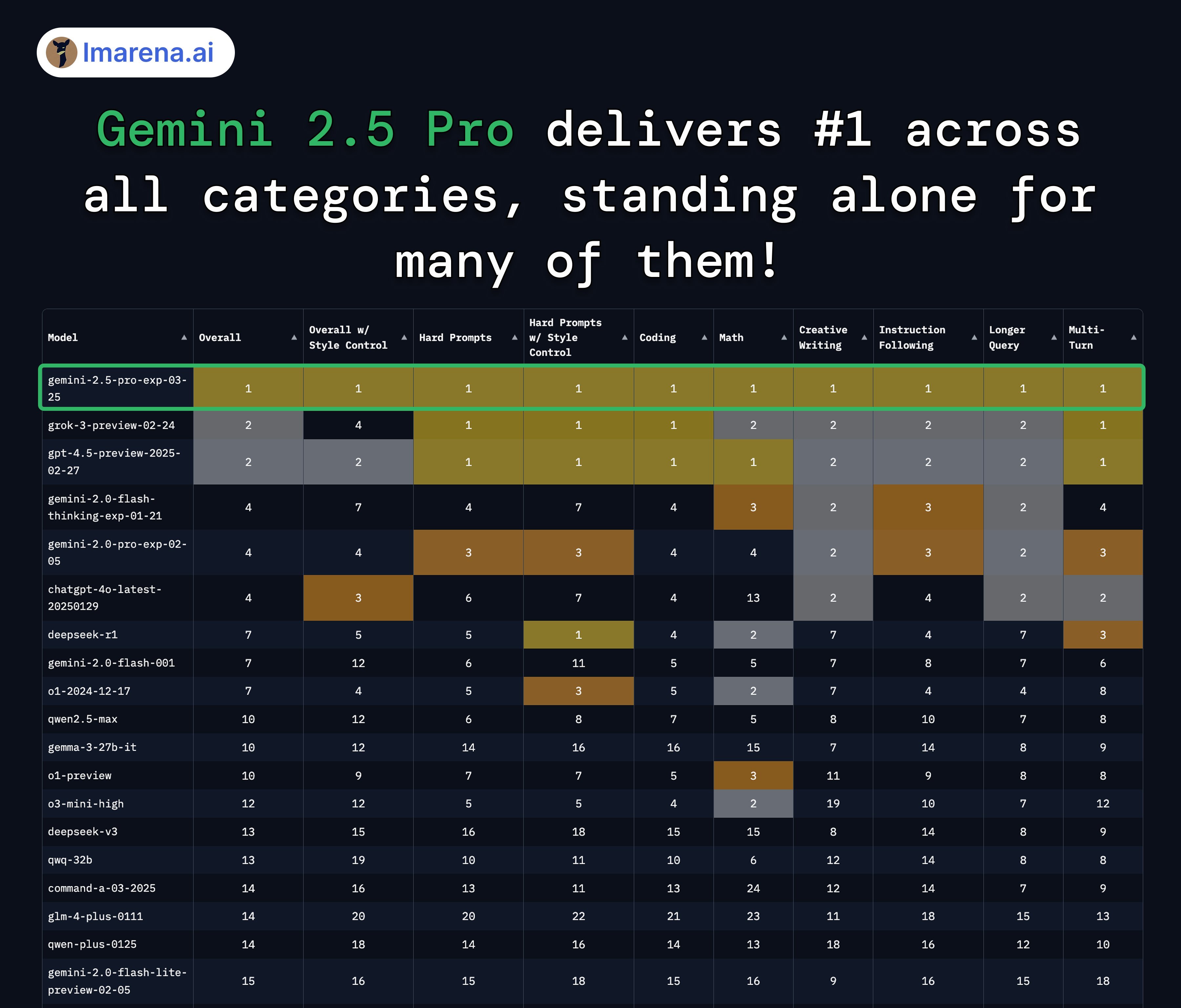
人類偏好測試 圖片來源:大模型競技場
在網頁開發領域,Gemini 2.5 Pro也是脫穎而出,在WebDev Arena上排名第二,它較上一代Gemini有了巨大的飛躍,超越了Claude 3.5 Sonnet,是第一款能與Claude抗衡的模型,但仍低于Claude 3.7 Sonnet。
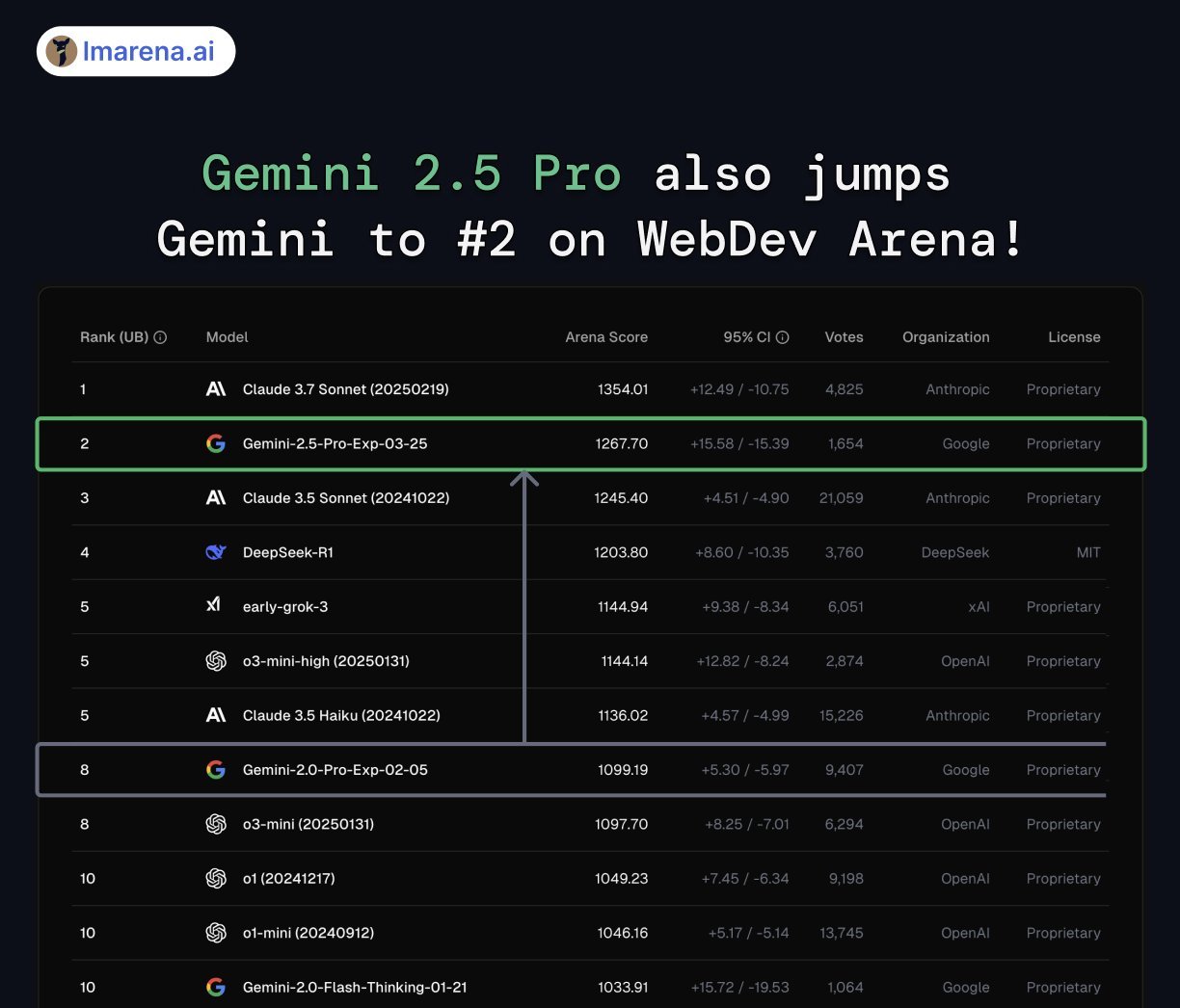
WebDev Arena測試 圖片來源:大模型競技場
在Vision Arena(視覺競技場)測試中,作為多模態模型的Gemini 2.5 Pro也處于領先的位置。
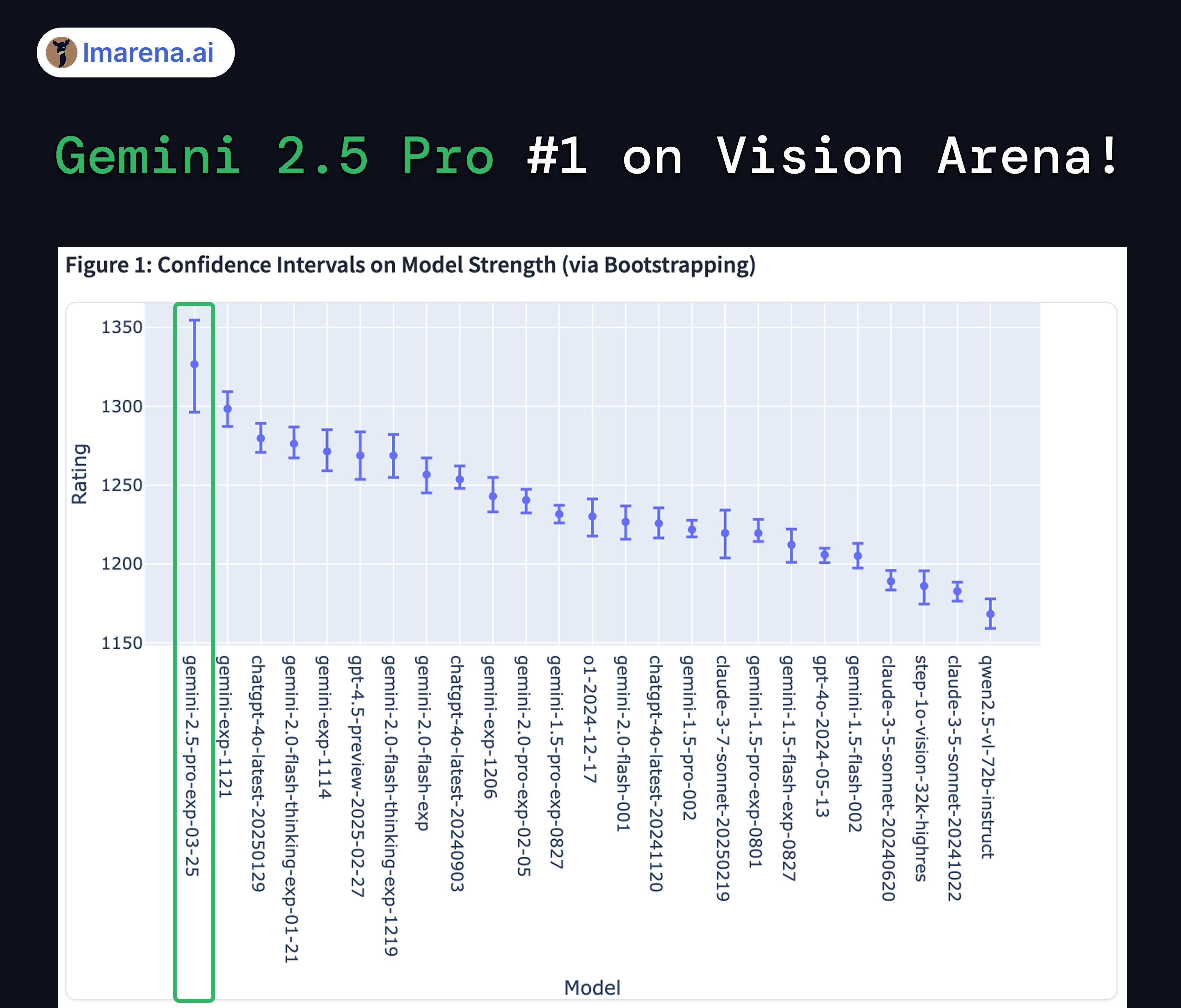
Vision Arena測試 圖片來源:大模型競技場
每經記者第一時間對Gemini 2.5 Pro進行了測試,測試包括數學、火星登陸模擬測試、網頁開發和小游戲制作。
數學問題
每經記者拋出的是一個博士資格考試的群論數學問題:有多少個147階的非同構群?
Gemini 2.5 Pro在數量和具體的非同構群上都給出了完美的解答。值得一提的是,此前記者也用這一問題對其他大模型進行了測試,Grok3、o3-mini和DeepSeek-R1都或多或少出現了錯誤,不是數量沒找對,就是具體的非同構群出錯。

火星登陸模擬
接下來,每經記者測試的是Gemini 2.5 Pro在數學和物理方面的綜合能力。測試選擇的是馬斯克的經典問題:繪制一個登陸火星并返回的火箭軌道圖。
Gemini 2.5 Pro給出了一個完成度超高的動態圖像,包含任務天數、具體軌道示意圖等要素。并且,它還稱,這只是一個簡單版本,如果允許它接入天體數據庫的話,它還可以制作一個更準確的版本出來。
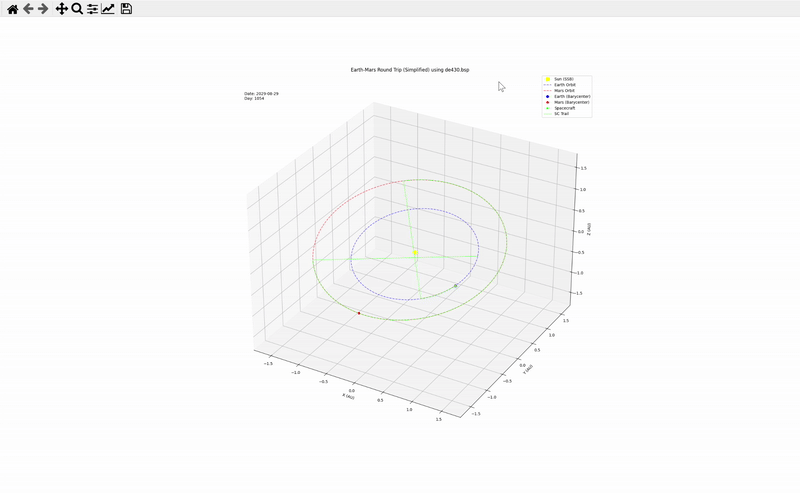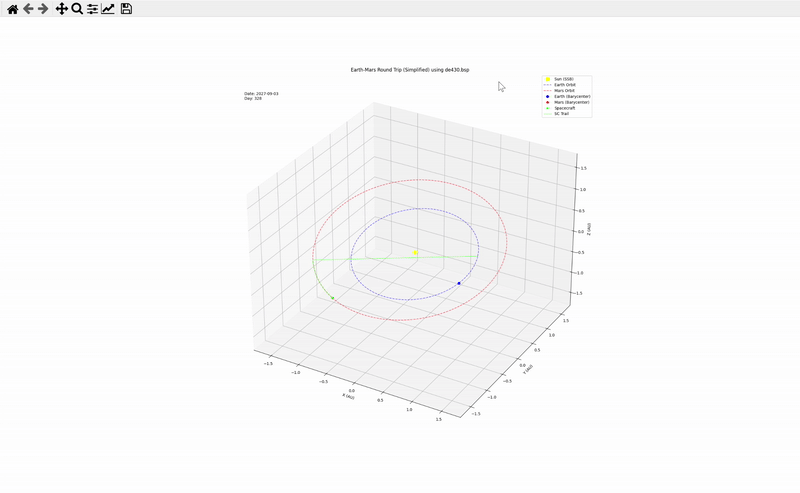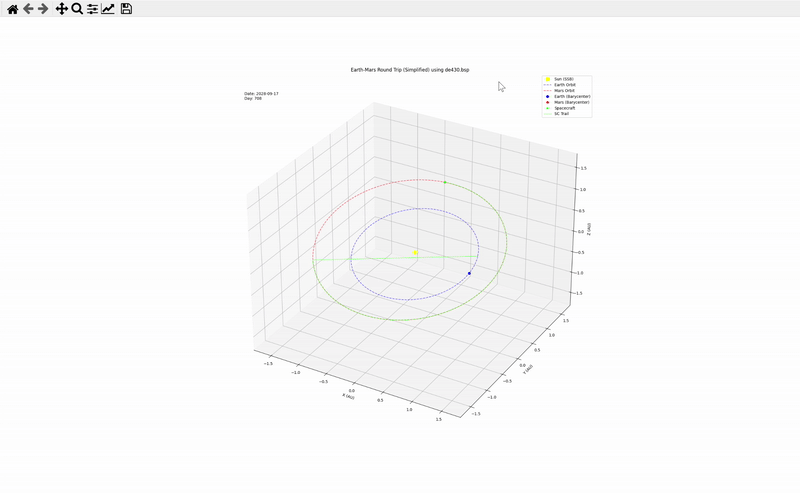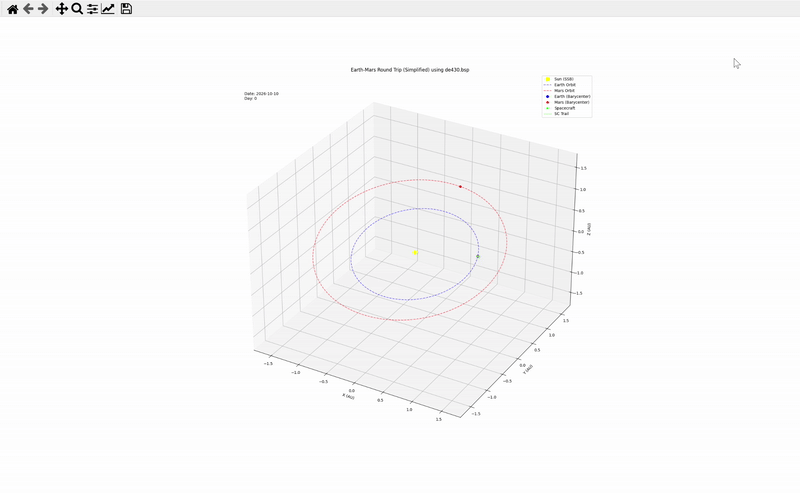
網頁開發
在前端設計方面,每經記者要求它設計一個有互動性的世界風光介紹網站。
Gemini 2.5 Pro輸出了一個完整的網站,并且帶有景點介紹和互動地圖探索相關功能。但是,在具體細節上,它犯了很多小錯誤,例如,景點介紹的圖片不僅單一,而且還都是不相關的內容。此外,整體網頁設計的色調也不甚美觀。
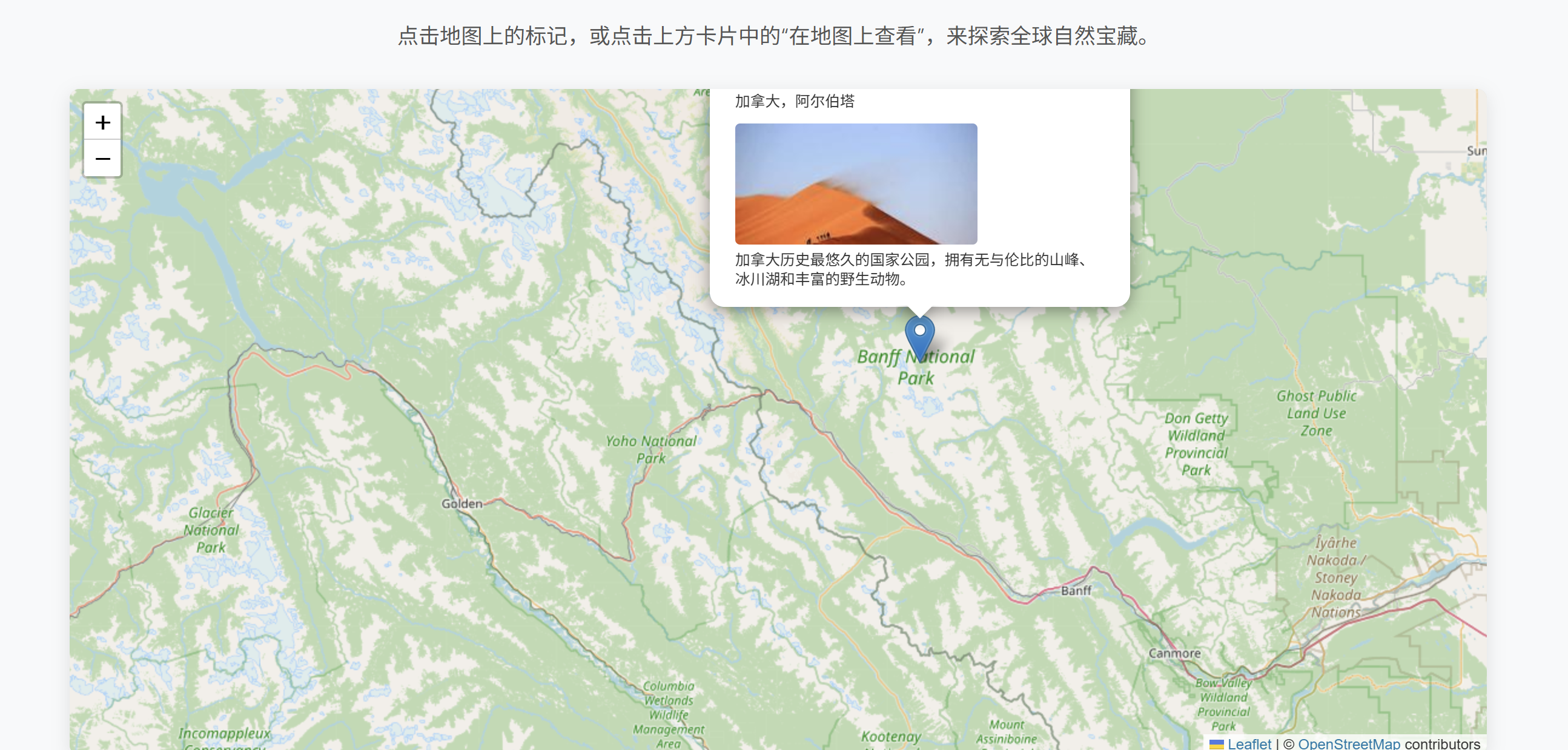
小游戲制作
最后,每經記者讓Gemini 2.5 Pro制作一個類似于flappy bird的小游戲,標準是卡通畫風,背景要隨游玩時間變換,玩家主角要是一個小飛象,要有有趣的玩法創新。
在短暫的思考后,Gemini 2.5 Pro輸出了完成這個游戲需要的500多行代碼。這一游戲非常完美地契合了每經記者給出的描述,并且對玩法創新的模糊描述也給出了良好的回應,自行思考出了無敵道具玩法,吃下金花生就可以在短時間內無敵。
更重要的是,這一游戲并沒有出現任何bug,只需要復制粘貼就可以流暢運行。
在此前的大模型測試中,第一次的輸出結果或多或少會出現一些bug,影響游戲體驗。不過,還是要指出的一點是,Gemini 2.5 Pro只考慮了背景變化的要求,卻沒注意到其生成的游戲背景圖案中,云朵變化速度過快,太費眼睛。
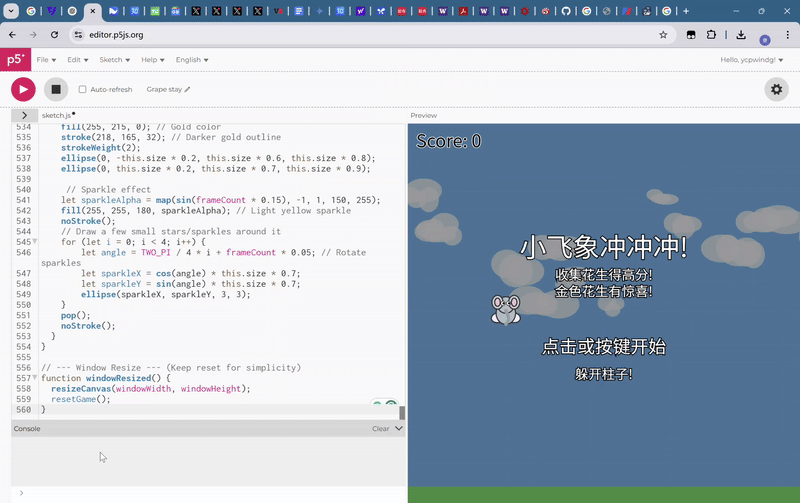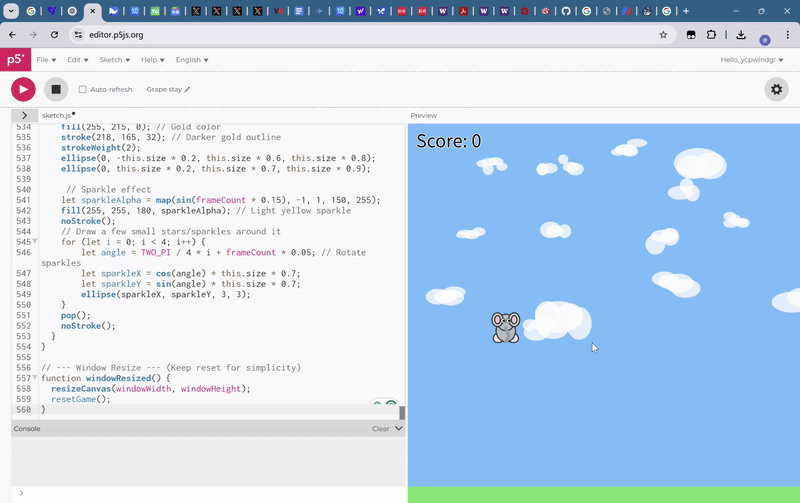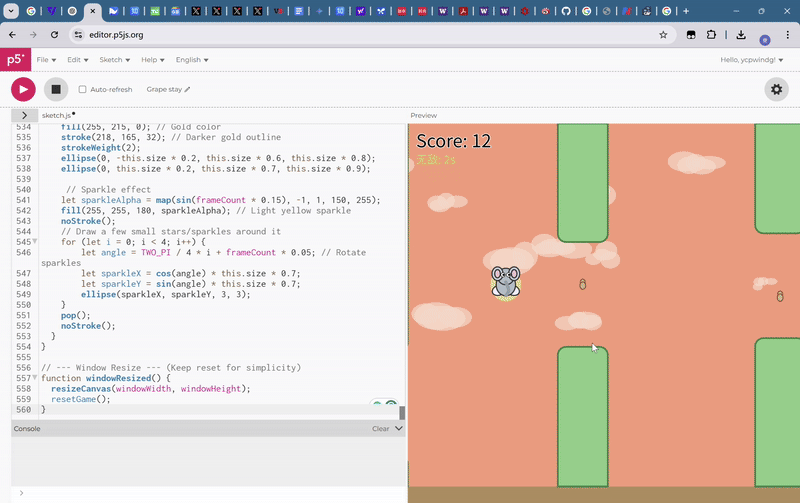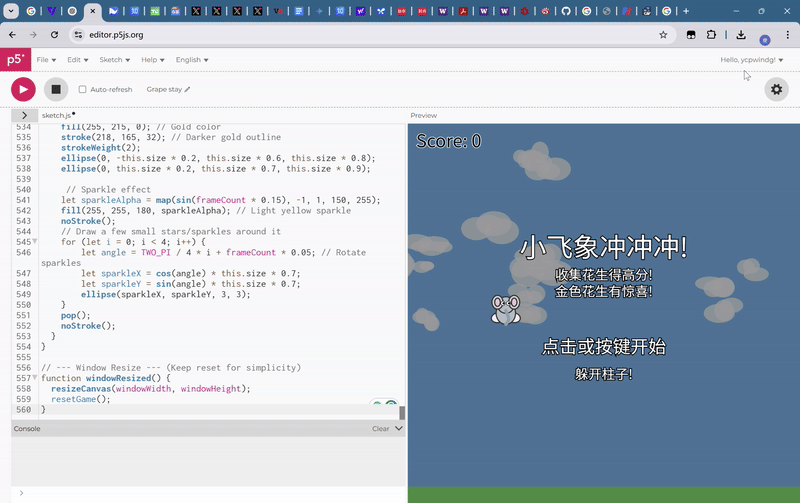
綜上,每經記者認為,Gemini 2.5 Pro在科學類問題和編程等硬實力上實力滿滿,但在審美和玩家體驗等軟實力上還有一點欠缺。
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














